Moderation
Moderating text for harmful content
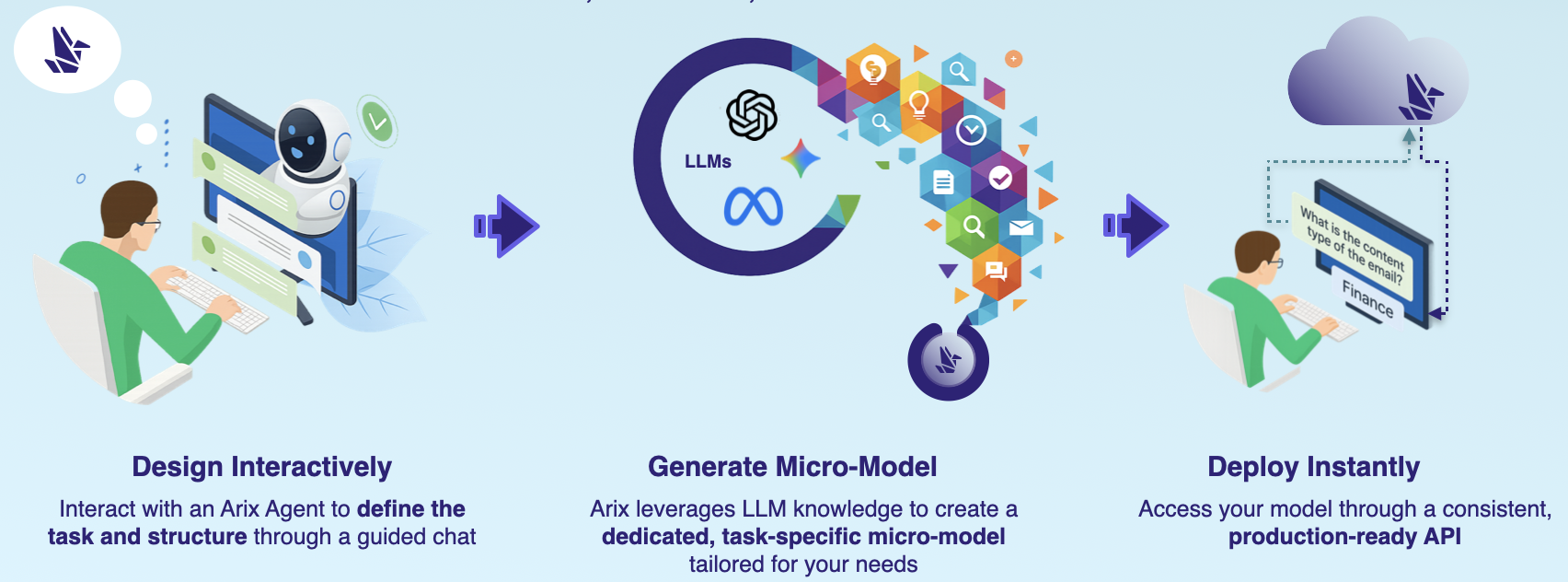
Build your micro-models that are structured, consistent, and free from hallucinations at a fraction of the cost
Only 5% of enterprise AI pilots reach full production.
MIT NANDA's GenAI Divide reports that most pilots never reach production due to limited customization, weak integration, and costly scaling challenges. LLMs perform well in open chat environments but break down in structured settings, where outputs must be consistent, formatted, and deterministic.
Over 60% of LLM Outputs Still Require Human QA
Even when deployed, LLM-driven systems exhibit high hallucination and error rates, both structural (format/schema) and semantic (content/task), making them unstable to integrate.
According to AI21, hallucination rates range from ~1–5% in general domains to over 60% in specialized tasks, forcing enterprises to build costly QA layers just to maintain reliability.
LLMs Are Too Slow for Real-Time Use-cases
Real-time enterprise workflows demand ~200 ms response times, yet large LLMs often exceed 500 ms. (GPT-4o averages ~760 ms to first token). Smaller, task-optimized models respond in 50–150 ms, making them the only viable choice for real-time, production workloads.

Our Solution
Reduce LLM cost by 80%
Better results than any single LLM
Deployment in hours
Secured and isolated
0 hallucinations or need for post-QA validation
Up to 10x faster inference time than traditional LLMs
Configured and tuned through chat
24/7 Support
We charge 20% of the savings we generate for you
Calculate the cost for processing your workload across different AI models
$3,250.00
$3,250.00
$4,400.00
(80% cheaper)
The difference looks small now...
But at production scale, this gap widens faster than your revenue does
Running 1M user posts for both policy violations and sentiment analysis, requiring two LLM calls for each review
Volume: 1M input texts | Prompt Size: 1,000 tokens | Output Size: 200 tokens